
Arquitectura limpia y microservicios parte 1
Pocas veces nunca he visto proyectos de microservicios que apliquen el modelo de arquitectura limpia propuesto por Uncle Bob, o al menos un modelo derivado que se aproxime. Es extraño como nos privamos de una estructura desacoplada y cohesiva a expensas de una comodidad efímera en tiempo de desarrollo, una comodidad que nos "ahorra" el esfuerzo de aplicar (entre otros) el principio de inversión de control. Y si nos situamos en un proyecto de servicios distribuidos donde las operaciones de entrada/salida aumentan por la naturaleza comunicativa de los microservicios vemos que se reduce aún más la aplicación de esta arquitectura, argumentando que solo encaja en sistemas monolito. Sin embargo esta última afirmación se desmiente si ponemos en su lugar los microservicios quitándoles el papel central en nuestros sistemas y viéndolos como lo que son, un simple mecanismo de activación de la lógica de negocio.
Síntomas de problemas

Cuando queremos reemplazar la librería X por la librería Y capaz de ejecutar consultas geo-localizadas para atender el nuevo feature que se viene en la siguiente versión de nuestra aplicación, y dicho cambio retrasa el lanzamiento porque requiere más de un sprint por la cantidad de archivos que compromete tenemos un problema, o al menos una sospecha de ello.
Cuando una modificación en la consulta a la tabla X de la base de datos Y genera más de tres archivos modificados en el git-commit (ignorando CHANGELOG.md) tenemos un problema, o al menos una sospecha de ello.
Cuando la actualización de las dependencias del proyecto rompe la aplicación porque la estructura de datos que provee la librería X deja de tener el campo <id: number> por tener el campo <identifier: number> y vemos que en más de un archivo se usa el campo id tenemos un problema, o al menos una sospecha de ello.
¿Cuál problema? Alto acoplamiento con detalles de terceros.

Una breve explicación de arquitectura limpia
El modelo de arquitectura limpia separa la lógica de negocio de los periféricos de entrada/salida, de sintaxis SQL, de estructuras de datos que se importan de una librería de tercero, del motor que renderiza las plantillas html, del formato en que se debe enviar la respuesta al cliente ya sea JSON o XML, evita que la lógica de negocio sepa si se le esta activando por una petición http o por un websocket o si se esta invocando desde un dispositivo android o iOS, etc. Todo lo anterior se convierte en mecanismos que ayudan a la lógica de negocio a cumplir su objetivo, pero nunca definen la forma en como la lógica de negocio cumple su objetivo. ¿Y cómo lo hace? El modelo teórico define la separación de la lógica de negocio con la regla de la dependencia la cual afirma:
Las dependencias del código fuente deben apuntar solo hacia adentro, hacia políticas de nivel superior.
El modelo dibuja la arquitectura como un conjunto de anillos anidados ubicando la lógica de negocio o "políticas de nivel superior" en el anillo central y aquellos mecanismos de entrada/salida de terceros en el anillo exterior. Si las dependencias apuntan desde los anillos exteriores hacia el anillo interior no se encontrarán sentencias de importación desde el módulo de lógica de negocio a un módulo de tercero como import MySqlModule from 'mysql', logrando así la separación deseada. La siguiente imagen representa lo anterior.
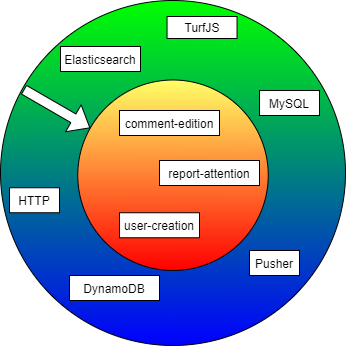
En la imagen vemos que los casos de uso como la atención de un reporte, la edición de un comentario y la creación de un usuario se ubican en el anillo interior y las tecnologías que ayudan a conseguir dichos casos de uso como Elasticsearch y MySQL se ubican en el anillo exterior.
Debo mencionar que el modelo que presento es una versión simplificada del modelo original pues éste último se compone de cuatro anillos dividiendo los dos anillos principales para hacer un mayor énfasis. Sin embargo, el modelo presentado aquí sigue la esencia el modelo original pues respeta la regla de la dependencia. Adicionalmente el autor del modelo original declara que se pueden modificar la cantidad de anillos mientras que se respete tal regla:
There’s no rule that says you must always have just these four. However, The Dependency Rule always applies.
-Rober C. Martin - Blog Clean Coder
Pero la lógica de negocio tiene efectos colaterales en algún momento, ¿No? Los casos de uso implican operaciones CRUD y/o invocaciones a otros servicios. Si bien los casos de uso no saben cómo se hace tras bambalinas dichas operaciones debe tener al menos una forma de invocarlas. ¿Como efectuar una consulta en una base de datos MySQL desde el caso de uso si no puedo hacer import MySqlModule from 'mysql'? Con el principio de inversión de control; todo caso de uso declara dependencia a interfaces, sería el anillo exterior quien le provee al caso de uso las implementaciones de dichas interfaces para que la operación de consulta se haga realidad cuando el caso de uso lo solicite. Con esto último la imagen del modelo queda como sigue:
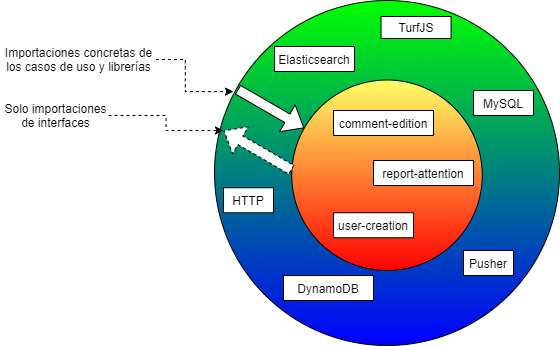
Con este modelo nos evitamos los síntomas de problemas mencionados anteriormente y una flexibilidad en reemplazar detalles de bajo nivel manteniendo limpio lo que importa en nuestro sistema: la lógica de negocio (o bien, los casos de uso). Además ganamos facilidad para probar la lógica de negocio al crear implementaciones dummy de cada dependencia que declare el caso de uso sin tener que aprender técnicas de mock como rewire o sinon.
La práctica

¿Y cómo podría encajar toda esta teoría en un proyecto de microservicios real? En SOSAFE tenemos cientos de microservicios y muchos de ellos sobre esta arquitectura. A la fecha de este escrito aún hay microservicios legado por fuera de la cobertura de esta arquitectura pero llegará el momento donde se integre a esta nueva práctica. Si bien no es una cobertura del 100% tenemos microservicios que cubren casos de uso clave para nuestro sistema, por lo que la aplicabilidad que expondré sí se basa del mundo real.
Lo que sigue es un ejemplo de como aplicamos la arquitectura limpia en parte de nuestro sistema con TypeScript y serverless, y como bonus una configuración de entorno de desarrollo local con depurador vscode que quizá te sirva.
Quédate en contacto para ver más...